Deployment Process
Once your model is trained, we automatically deploy it to our inference server, making it accessible for inference tasks. You can choose the deployment option that best suits your needs:- Hosted Inference UI: Access the web interface provided by our platform and upload images to make predictions using the trained model.
- REST API: Interact with the hosted API using SDKs or directly via HTTP calls to perform inference tasks programmatically.
Hosted Inference UI
Our Hosted Inference UI provides a user-friendly web form that allows you to upload images and make inferences using your trained model. Simply upload an image through the web interface, and the model will perform predictions, providing you with the results in a clear and intuitive manner. This option is ideal for quick and interactive model testing and evaluation.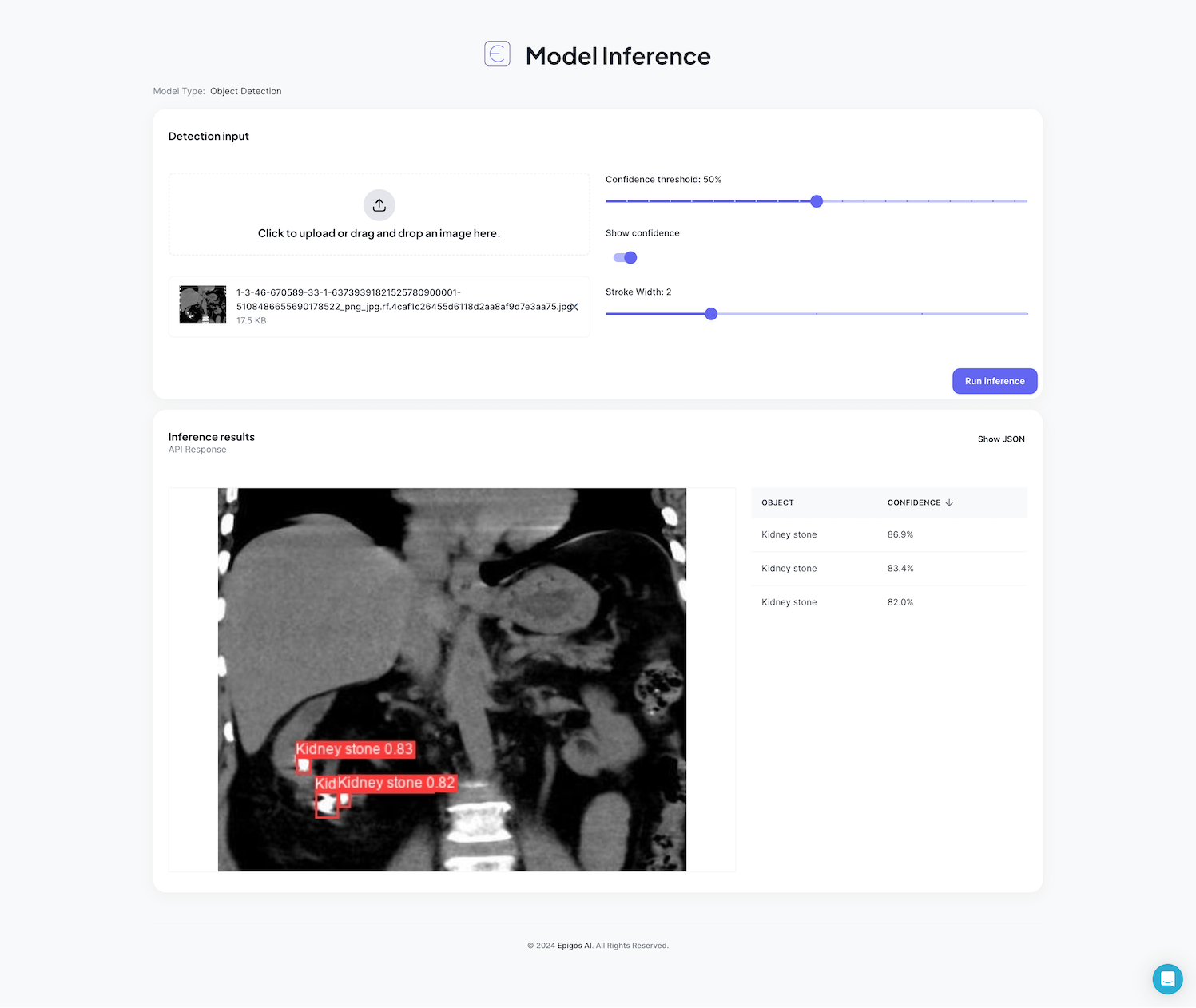
REST API
Our Hosted REST API offers a scalable and reliable solution for integrating your trained models into applications and systems. With the REST API, you can interact with the model using SDKs or directly through HTTP calls. Images for API requests should be provided in base64 encoded string format. The API response includes the model’s predictions, and for object detection tasks, it also contains the annotated image with bounding boxes and labels overlaid.REST API
Get started with our API guide.
Python SDK
Integrate Epigos into your Python application.
Node.js SDK
Integrate Epigos into your Node server.
Integration and Usage
Integrating your trained models into your applications and workflows is straightforward with our deployment options:- Web Interface: Share your Hosted Inference UI link to enable users to interact with the model seamlessly.
- API Integration: Utilize the REST API endpoints within your applications to perform inference tasks programmatically, enabling automated predictions and real-time decision-making.